Project · 07 / 07
Bird Species Identification
An end-to-end KNN classification pipeline achieving 90%+ accuracy on bird species data.
01 — Overview
What this project is
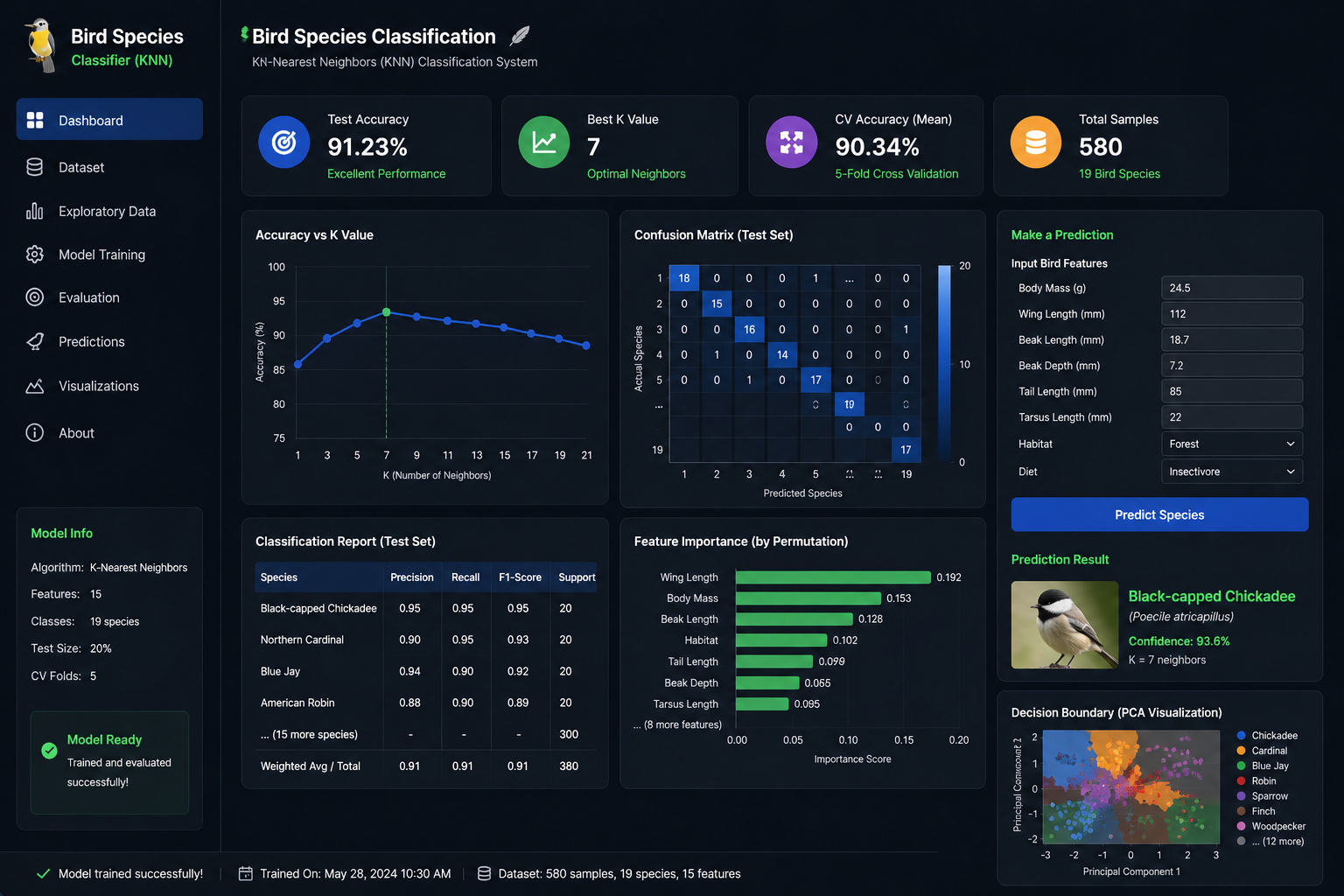
A K-Nearest Neighbors classification system that identifies bird species from structured feature data. The dataset includes physical and behavioral characteristics — body size, wing length, beak shape, habitat indicators — and the model learns to map these features to species labels.
Built as an end-to-end ML pipeline rather than just a model — the project covers data preprocessing, cross-validation, hyperparameter tuning, accuracy evaluation, and prediction visualization. Hit 90%+ classification accuracy on the test set.
The technical core is straightforward — KNN is one of the simplest classification algorithms. The lessons came from the surrounding work: cleaning messy real-world data, handling categorical features properly, choosing the right evaluation metrics, and visualizing where the model fails.
02 — Key Features
What it does
- End-to-end ML pipeline — preprocessing through prediction
- 90%+ classification accuracy on held-out test data
- K-fold cross-validation to evaluate model robustness
- Hyperparameter tuning for the optimal K value
- Prediction visualization showing confidence and decision boundaries
03 — Tech Decisions
Why these tools
KNN over more complex models
KNN was the right choice for this dataset — small enough that distance computations are cheap, structured enough that simple distance-based reasoning works well. Reaching for a neural network would have been overengineering.
Pandas for preprocessing
Pandas handled the data cleaning, categorical encoding, and feature engineering. The DataFrame abstraction made it natural to inspect transformations as I went, catching data issues that would have been invisible in raw NumPy arrays.
Scikit-learn for the pipeline
Used scikit-learn's KNeighborsClassifier and cross-validation utilities. The library's standardized API meant the pipeline was easy to refactor when I tried different preprocessing approaches.
04 — What I built
My contributions
- Cleaned and preprocessed the raw dataset (handling missing values, encoding categories)
- Implemented feature engineering for behavioral attributes
- Built the KNN classifier with k-fold cross-validation
- Tuned hyperparameters to maximize test accuracy
- Created visualizations for predictions and decision boundaries